我们中国人常常把知识分子称为“读书人”,又把上学做研究叫做“念书”。不过,今天我想谈谈如何“不读书”还能做研究,而且也能取得有趣的研究成果。
做研究虽然要看书,但是没有研究者能看完所有的书。斯坦福大学英语文学系的教授Franco Moretti说,文学作品不能一本一本地读。为什么呢?因为太多了,读不完。他说“光是19世纪的英国就有三万部小说,总共也许有四万、五万、六万部,没人全部读过、今后也没人能全部通读一遍。此外,还有法国小说、中国小说、阿根廷小说、美国小说……”要是把这些小说都读一边才能研究世界文学,那世界文学就没人能研究了。
那么怎么办呢?Moretti建议,只能要么只读名家名著,要么只读一个国家一个地域的作品。但无论怎样,都有画地为牢、见树不见林的危险,难以把握一个时代整体的文学样貌,更无法看清不同国家的文学作品之间的关联。
就像庄子说的,“吾生也有涯、而知也无涯,以有涯随无涯,殆已。”就是说,书太多了,我们的生命有限、记忆力和语言能力也都有限,所以,算了吧,别折腾了。你还不如不读。
不过,Moretti还是和庄子不同。虽然他们不鼓励我们拼命死读书,这并不妨碍他们对知识的追求。但是“不读书”,怎么追求知识呢?
不读书,还想获得知识,就要用到一种叫做“数字人文”的方法。
数字人文的方法很多,这里先谈一个数数的办法。数数是什么呢?对研究英语文学的学者来说,就是数单词,就是看看每个单词在一篇文章或者一本书中出现了多少次。当然,这不是让你一个字一个字地数,而是利用计算机去数。计算机在做这种简单重复劳动的时候,比人准确有效得多。数完之后,我们就可以按照每个单词出现的次数(词频)把所有单词放在一起排个序,然后根据高频词来推测这部作品的主题和风格。
当然,这个推论的部分,计算机是无法代劳的。要做出合理的推论,研究人员还是要对相关作品有一定的背景知识,而且最好是对多部作品同时进行高频词分析,在相互参照中发现每部作品的突出特征。
几年前,纽约时报就用这种方法分析了1789年到2009年之间所有美国总统的就职演讲,让读者一目了然地看到在美国200多年的历史进程中,总统关心的核心问题是如何变化的。比如,最早的几位美国总统在就职演说中最常提到的都是跟政治结构、公民权利、公共利益相关的词(如“政府”、“宪法”、“立法机构”、“公民”、“公共”、“义务”、“利益”等)。到了20世纪中叶,美国总统就职时最爱说的则变成了和美国的世界领袖地位及其意识形态相关的词汇(“世界”、“力量”、“自由”等)。20世纪80年代以后,总统就职演说的重点又发生了变化了,他们开始把“工作”、“世代”、“梦想”之类的词挂在了嘴边。


美国总统约翰·亚当斯在1797年的就职演说(来源:纽约时报)

美国总统哈里·杜鲁门在1949年的就职演说(来源:纽约时报)

美国总统贝拉克·奥巴马在2009年的就职演说(来源:纽约时报)
这种不读书的方法,我们可以把它叫做“词语口袋法”。叫它“词语口袋法”,意思就是说它好象是把一篇文章一个词、一个词地剪下来,扔进一个口袋里,完全不管上下文和语法语序,只是去数每个词出现了多少次。在这个方法里,“我打他”和“他打我”完全没有区别,反正都是“我”、“他”、“打”三个字各出现了一次。
这个方法最大的问题是,它过分简化了语词和语义之间的复杂关系。比方说,“我打他”和“我打球”中都出现了一个“打”字,但是含义是明显不同的。“我打了他”和“俺揍了那傢伙”表面上看起来,遣词造句的重合度不高,但是语义却是很相近的。这么一来,大家可以看到,这种“不读书”的方法就显得有些不靠谱了。
这个时候我们就要反思一下,问问我们自己到底是怎么判断出“我打他”和“我打球”中的“打”字具有不同含义的。显然,我们是根据宾语的不同推断出来的。换言之,一个词的语义在很大程度上是由它的上下文(也就是和它相邻的词)来定义的,有点儿像俗话里说的“欲知其人,先观其友”。
在一段话或者一篇文章里,总是和一个词扎堆儿出现的就是这个词的朋友,我们可以根据它的这些朋友来推测这个词在这段话或这篇文章里的含义。这样一来,计算机就又能帮助我们了。
当然,这次它要做的工作复杂了一些。它不能只去数数了,它得看哪些词语是扎堆儿出现的。它得把那些和“篮球”、“操场”、“运动员”等词语扎堆儿出现的“打”字跟这些友词分为一组,再把跟那些和“受伤”、“生气”、“流血”等词语一同出现的“打”字分在另外一组。每个分组就代表了一个特定的主题,前一个是跟运动有关的,后一个是跟暴力有关的。这样,我们就能更加准确地判断出一篇文章或者一本书中有哪些主题了。
当然,我这里说的比较简单,在实际操作中其实是一个引入了概率模型和迭代算法的复杂程序,我们把它叫做主题模型法(topic modeling),可以看作是词语口袋法的一种延伸。
这种“不读书”方法,能让我们获得什么样的成果呢?
Jockers是一位研究19世纪末、20世纪初的爱尔兰文学和爱尔兰裔美国文学的学者。有好些年,他在斯坦福大学和Moretti合作办了一个斯坦福文学实验室(Stanford Literary Lab)。五年前,他出版了一部名为《宏观分析》(Macroanalysis)的书。虽然这部书的研究对象是19世纪英语国家的文学作品,而非世界文学,但是在很大程度上算是把Moretti的想法付诸实践了。
本书研究的范围,不是一部、两部19世纪的英语文学作品,而是把斯坦福文学实验室收集到的3346部作品放在一起研究。Jockers想知道这些19世纪英语文学作品在主题和风格上都有哪些特征,他想看看这些特征会不会因为作家的性别、国籍不同而有所不同。
不过,正如Moretti所说,Jockers不可能把这3346本小说全部通读一遍。那怎么办呢?Jockers决定他不要读书,他要让计算机去帮他读,他只负责设计算法、写程序、做解读。主题模型法就是他使用的主要方法之一。通过主题模型法,他在3346部作品中识别了几百组扎堆儿出现的词汇,每组词汇都代表了一个特定的主题。比如下面这个包含了“印第安”、“印第安人”、“酋长”、“野蛮人”、“来福枪”、“战争”、“荒野”、“独木舟”等词汇的词群,我们就可以把它理解为一个有关美洲土著(即印第安人)的主题。
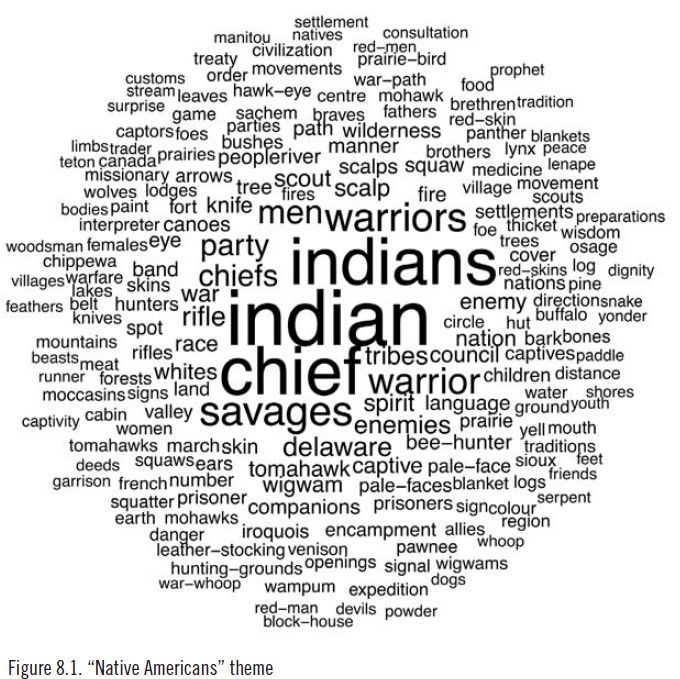
“美洲土著”主题(来源:Matthew Jockers, Macroanalysis)
通过分析不同主题在这3346部作品中的分佈,Jockers得出了一些很有趣的结论。譬如说,女作家喜欢讨论“情感与幸福”、“时尚”、“婴儿”这些主题,而男作家喜欢写“混蛋与叛徒”、“争吵与决斗”之类的东西。再譬如说,美国小说常常讨论奴隶制度、印第安人、城市和边疆,苏格兰小说动不动就说到商人与贸易、巫师与巫婆、金银财宝、君主和骑士,而爱尔兰小说则经常写到关于地主与佃农的事情(这个倾向在19世纪上半叶尤为明显)。此外,爱尔兰小说家也比其他国家的同行们更关注个人品质、幽默感、人物的喜怒哀乐。
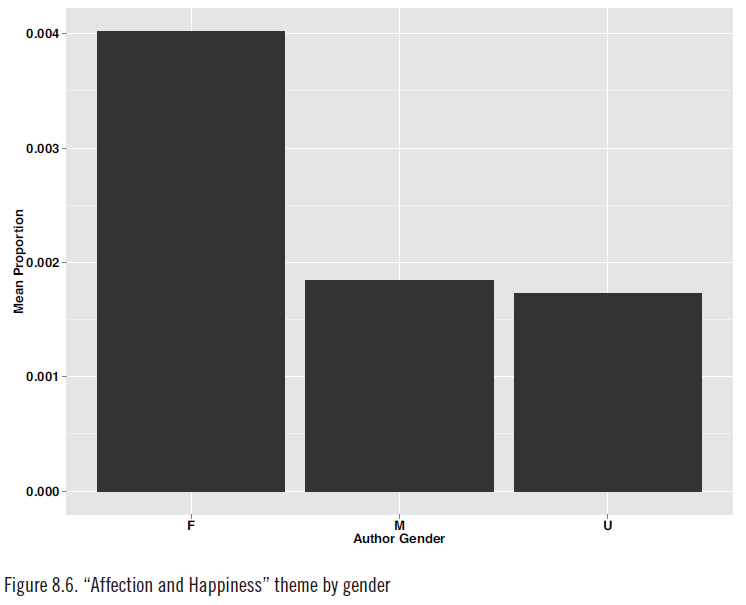
不同性别小说家的作品中“情感与幸福”主题出现的比例(来源:Matthew Jockers, Macroanalysis)
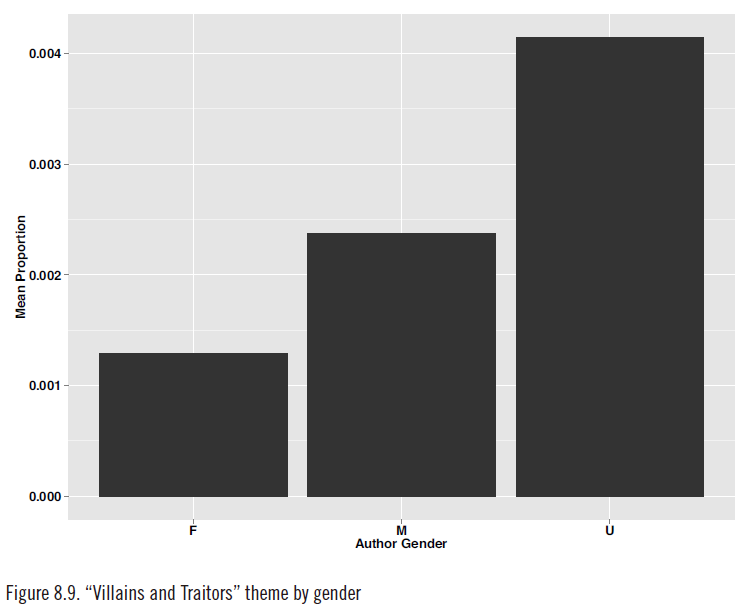
不同性别小说家的作品中“混蛋和叛徒”主题出现的比例(来源:Matthew Jockers, Macroanalysis)
最重要的是,Jockers不可能通过一本一本地读书获得这些发现,他甚至也不可能通过对十几部或者几十部作品的仔细研读、深入分析获得这些发现并且说服读者的。换句话说,虽然说书籍是知识的海洋,你不先放弃传统的阅读方式,是不能获得这样的知识的。
细心的你也许已经发现,那就是这些扎堆出现的词群里基本上都是名词、动词、形容词之类的实词,其他的如人称代词、冠词、介词等都被排除在主题模型之外了。道理很明显:代词、冠词、介词跟一部作品的主题没多大关系。——但是,这些词仍然值得引起我们的注意。为什么呢?因为这些词往往跟作品的风格息息相关。
有些文学体裁往往较多地使用跟方位有关的介词和指示代词,而某些作家的个人风格则是不喜欢用冠词和某些标点符号。
Jockers也对此也进行了分析——他仍然是藉助计算机程序,本质上仍然是数数,当然具体的算法会有些不同。一句话,自己“不读书”,让计算机读书。通过算法,Jockers对三千多部英语小说在主题、作品风格等方面进行了系统的、详尽的研究,并对照作家的国籍和性别进行了交叉分析。这个分析是量化的,所以结果是Jockers给每部作品都算出了一组数。每组数中包含578数值,分别定义了这部作品的主题和风格的方方面面(比如这部作品有多大比例是关于情感主题的、有多大比例是关于决斗主题的、在多大程度上倾向于使用不定冠词和分号等等)。根据这些数值,他就能计算出任何两部作品之间的相似度。
这个有点像我们在地图上测量两个地点之间的距离。只要我们知道了每个地点的经度和纬度,我们就能知道它们在地图上的什么地方,就能把它们之间的距离给算出来。
不同的是,在Jockers这里,地理位置变成了文学作品,而每个文学作品的位置不是由经度、纬度这么两个数值确定的,而是由578个数值共同确定的,但是道理是一样的(用科学术语来说,地图是一个二维空间,而Jockers构建的是一个578维的空间,每个作品都是这个空间里的一个点,它在每个维度上都有一个值,它的578个值共同定义了它在这个多维空间里的位置,而不同作品之间的相似度就可以理解为它们在这个多维空间里的距离,距离越近、相似度就越高)。
当Jockers算出任意两部作品的相似度之后,他就画了一幅图。这个图里面,每个点就是一部小说,相似度越高的小说在图上的距离就越近;他还给每个点上了色,男作家的作品用蓝色、女作家的作品用红色,结果我们看到这些小说自动就扎堆儿了。换句话说,男作家的作品彼此之间相似度很高,它们都群聚于这幅图的上半部分,而女作家的作品彼此之间相似度也很高,聚集于这幅图的下半部分。不同性别作家的作品彼此之间,则通常是差异极大、泾渭分明的。

不同性别小说家的作品中主题与风格的差异(来源:内布拉斯加大学官网)
然后,Jockers又给这些作品按出版日期重新著了一次色,出版日期越早,颜色就越浅。于是,我们看到了下面这幅图。显而易见,即便在19世纪这一百年中,主题和风格随着时间的推进也有着明显的变化,而出版时间接近的作品在主题和风格上的相似度一般也是较高的。

19世纪不同年代的作品中主题与风格的演变(来源:内布拉斯加大学官网)
谈了这么多19世纪的英语小说,也该谈谈汉语作品了。用主题模型法分析汉语文献有一个特殊的困难——那就是“分词”的问题(这里我说的不是标点符号里的那个分词,是指用计算机将汉语文本以词为单位逐词分开)。我们知道英语的每个单词之间都是用空格隔开的,但是汉语文献中没有空格。我们要么就以字为单位进行分析(也就是说,数数每个汉字在不同的书里各出现了多少次,这样的话,“陛下”就要拆开成“陛”和“下”这么两个字来数)。要么我们就得先对汉语文献预先进行分词处理,这就增加了难度。
尽管有这些困难,这些年还是有学者另辟蹊径,陆续做出了些有意思的成果来。我拿德龙(Donald Sturgeon)的研究做个例子。德龙还在读博士的时候就凭一己之力做出了一个巨大的线上开放电子图书馆,虽然名字叫作“中国哲学书电子化计划“,但是事实上它收藏了超过三万部中文著作,从先秦到民国,凡所应有、无所不有,总共有五十亿字之多。
德龙很喜欢研究中国古人的“剽窃”现象。他发现中国文献中——尤其是先秦和秦汉文献中——经常有不少“相似段落”,有的时候是几个字,有的时候则是一大段话。有时候,我们的老祖宗会注明出处,坦白地告诉我们他们在引用哪本书里的东西,但是有时候他们就三缄其口、秘而不宣了。
一般来说,一部作品总是倾向于引用跟自己观点相近的其他作品,那么通过对不同作品之间的相似段落的分析,就可以看出哪些作品是惺惺相惜的。虽然先秦两汉的典籍没有19世纪的英语小说那么多,但是这个德龙也是一个不愿“读书”的人。所以他写了一个程序,专门寻找中文文献中的相似段落,还把这个工具挂在了他的电子图书馆里,供大家免费使用。
他的方法和主题模型法关系不大,但是他也是通过比较不同文本的遣词造句来度量它们之间的相似度。计算完了相似度之后,他也绘制了一张图,把一部部中国典籍用一个个点在图中表示出来,相似度越高,距离就越近。为了方便读者,他还把相似的作品群用不同的颜色区分开来。结果我们发现,这些先秦典籍自动归队了。
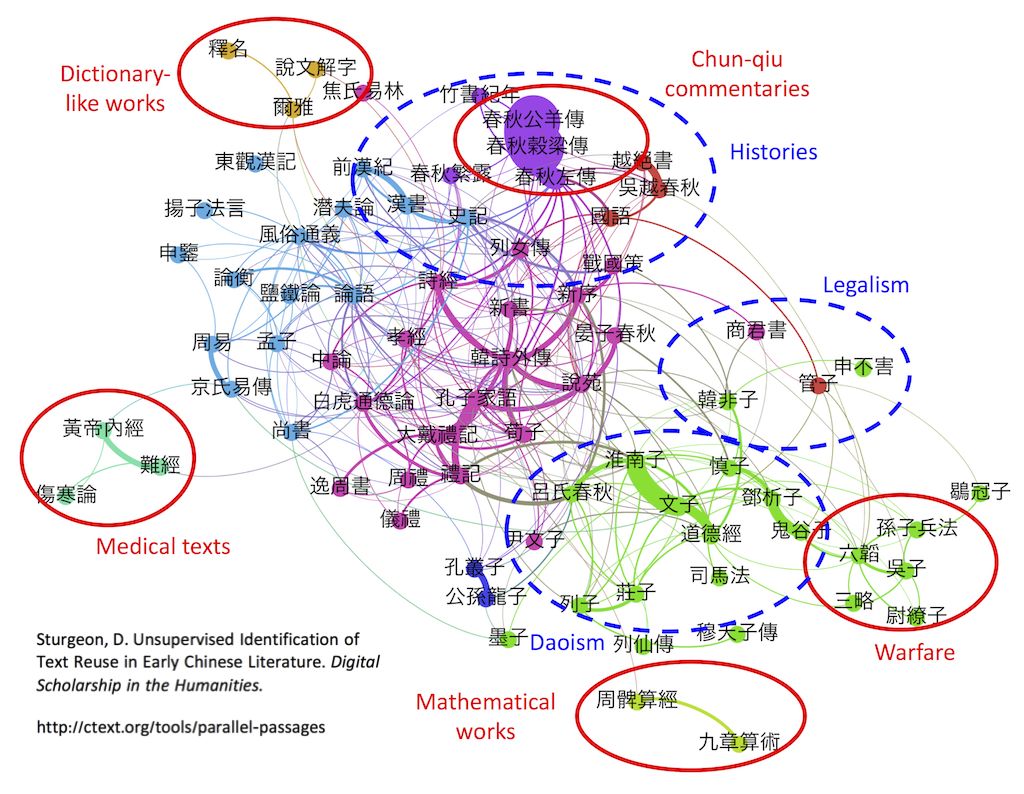
早期中国文献的相似度(来源:中国哲学书电子化计划官网)
大家可以看到,关于春秋时期历史的春秋三传聚到了一起,周围是跟先秦历史有关的其他古籍,比如《绝越书》、《吴越春秋》、《竹书纪年》之类。字典类的《说文解字》、《尔雅》等也聚到了一起,法家、兵家、道家、儒家、算书、医书等等也都各从其类。不过,我个人看这幅图,觉得最有趣的是《孟子》和《荀子》的位置。晚唐北宋以前的很长一段时间里,荀子在儒家里面的地位其实高于孟子的,直到宋代道学兴起了,孟子的地位才得到擡昇,“孔孟之道”才成为口头禅。在德龙的这张图里,很有趣的是,《荀子》和《礼记》等书是聚在一起的,和法家、老庄之流的作品距离也不远。倒是《孟子》和《论语》相似度相当地高,并且与《尚书》、《周易》、《春秋》等西周或春秋时代的儒家典籍成了邻居。不知道像二程、朱熹那样尊孔孟、抑荀子的道学家看到这幅图,会不会笑得从墓里坐起来?
数字人文另一个方法是“挖矿”。所谓“挖矿”,准确地说,叫作数据挖掘(data mining)。它是把一个文本当作一个蕴藏了丰富数据的大矿山,数据就是里面的矿藏。研究人员的任务就是要把这些数据从文本中挖掘出来。
这些数据可以分为两类,一类是描述实体本身的属性的,另一类则是描述实体之间的关系的。什么是实体呢?一个“实体”可以指任何东西,它可以是具体的,也可以是抽象的。我们可以把地点作为一种实体,也可以把官职、人物、著作、时间或者其他任何有形或无形的东西作为一种实体。每种实体都会有很多属性,头衔、级别就是官职这个实体的属性,姓名、字号、年龄就是人物这个实体的属性,而地名、行政层级、经纬度则是地点这个实体的属性。我们可以把世界上发生的事情理解为实体之间的关系。比如,“庆历五年以欧阳修知滁州”(用我们今天的话说,就是在1045年欧阳修被任命为滁州知州)。这件事就可以理解为欧阳修这个人物实体、知州这个职官实体、滁州这个地点实体、还有庆历五年这个时间实体之间发生了关系。数据挖掘的任务就是要利用计算机识别和解读文本中对这些实体及其相互关系的描述,把这类信息提取出来。
这种数据挖掘通常需要用到两个技术,一个是关键词搜索,一个是模式搜索(pattern search)。要把文本中提到的各类实体挖出来,在算法上是相对容易的。很多时候,只要我们准备好一套关键词列表(比如一份人名表、一份年号表、一份地名表),然后让计算机用这些关键词一遍一遍地在文本中搜索,就可以把其中提到的人名(欧阳修)、年代(庆历五年)、地名(滁州)找出来了。
但是计算机怎么知道这三个不同实体之间的关系呢?这时我们就需要使用更加复杂的模式搜索了,关键词就没用了。
由于我们的语言是遵循着一定的法则的,我们根据这些法则把词汇组织起来,用以表达特定的含义。上述的例子用的就是文言文中表达官员任命的一个常见句式:时间+以+人名+知+地名。这个句式就是我们这里讲的“模式”。通过把这个句式用计算机算法表达出来,让计算机在文本中搜索这样的句式,我们就能在相关时间、人名、地名之间建立起正确的关系了。
当然,我们的语言表达方式是相当灵活和丰富的,同样的意思也可以通过不同的句式表达出来(如“欧阳修贬知滁州,时庆历五年也”等等)。这无疑增加了模式搜索的难度。不过,由于常用句式的数量是相当有限的,因此我们通常可以通过很少的几种模式识别和提取文本中描述的大量的实体关系,这些既包括人物与职官、任职地之间的关系,也包括人物与其籍贯地之间的关系,还包括人物与人物彼此之间的亲属、师友、举荐等等社会关系。
通过大量的数据挖掘工作,我们就可以将浩如烟海的描述性文字转变为海量的数据,并在此基础上,构建出一个强大的数据库。近些年由哈佛大学包弼德教授牵头、在包括北京大学和中央研究院在内的中外诸多学术机构通力合作下建构起来的中国历代人物传记资料库(CBDB),就是这样的一个例子。
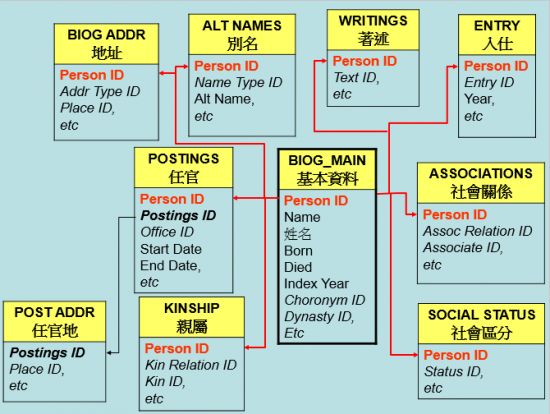
一个高度简化的中国历代人物传记资料库的数据结构模型
当我们利用计算机代替我们去阅读史料、提取了数据并建立了数据库以后,我们就可以直接向数据库提出我们的研究问题了。譬如,我们可以探讨在中国历史上像欧阳修这样担任知州的中高层官员都是来自哪个地域啊,他们彼此之间是不是亲戚啊,诸如此类。这样的问题可以引导我们发现中国历史长河中的宏观变化。
下面这两张地图就是笔者在CBDB开发团队通过“挖矿”得到的大量历史数据的基础上绘制出来的,第一张图展示的是1040年代担任知州的宋代官员来自哪些地域,而第二张图则展示了1210年代担任知州的宋代官员的出身地。
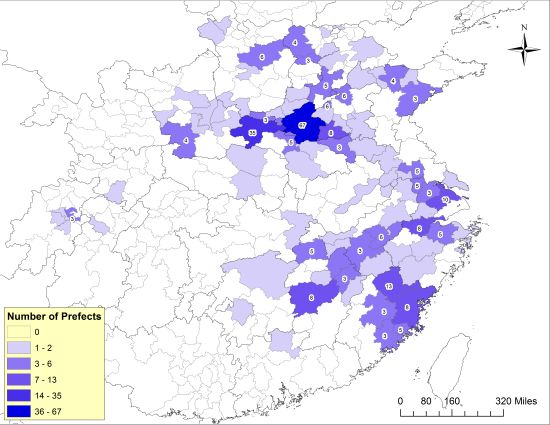
1040年代北宋知州的出身地 (来源:陈松,“Governing a Multicentered Empire”)
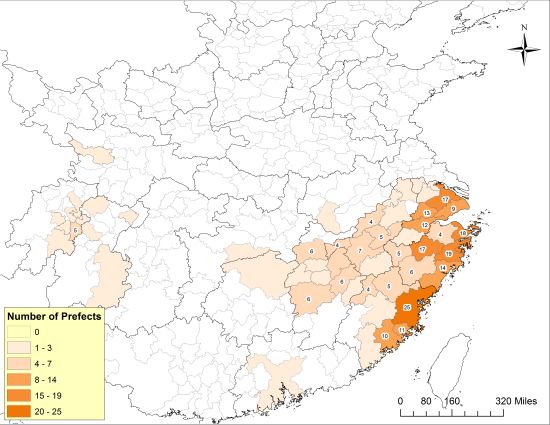
1210年代南宋知州的出身地 (来源:陈松,“Governing a Multicentered Empire”)
通过这两张图的对比,我们看到在北宋中期(1040年代),以这些知州为代表的北宋政治精英主要来自开封府和河南府(也就是北宋的东京和西京——即下图正中间的两块深蓝色区域),这一点和唐代政治精英聚集於长安、洛阳两京的情形颇为相似。而到了南宋时期(1210年代),大量的知州出身于沿海各州府,行在临安府(今杭州)出身的官员则并未表现出明显的优势。这个现象出现的原因非常值得探讨。非常可能的解释是,这意味着北宋中期以来科举的兴盛和东南沿海地区经济文化发展给这些地区的家庭带来了前所未有的政治机会。
所以,这里说的“不读书”并非是什么书都不读,而是藉助计算机技术用一个新的方式去读书。Franco Moretti把这个叫做“远距离阅读”(distant reading)。我们古人有句话说道,“不识庐山真面目,只缘身在此山中”。远距离阅读有个好处,就是让我们跳出亲身体验这个庐山,让我们凭借计算机技术飞上云端,鸟瞰19世纪的文学作品、中国早期的文献资料或者其他图书典籍,从而发现那些光靠精读、细读难以发现的文献特征。
这是近年文史哲领域方兴未艾的一个新方向,叫做“数字人文”(digital humanities)。借助于算法,我们可以看到文史哲文献中很多用传统阅读法无法看到的东西。

 狗仔卡
狗仔卡 发表于 2018-7-18 10:59 PM
发表于 2018-7-18 10:59 PM
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡